Section:
New Results
Self-Attention Temporal Convolutional Network for Long-Term Daily Living Activity Detection
Participants :
Rui Dai, François Brémond.
This year, we proposed a Self-Attention - Temporal Convolutional Network (SA-TCN), which is
able to capture both complex activity patterns and their dependencies within long-term
untrimmed videos [34].
This attention block can also embed with other TCN-nased models.
We evaluate our proposed model on DAily Home LIfe Activity Dataset (DAHLIA) and Breakfast
datasets.
Our proposed method achieves state-of-the-art performance on both datasets.
Work Flow
Given an untrimmed video, we represent each non-overlapping snippet by a visual encoding over
64 frames. This visual encoding is the input to the encoder-TCN, which is the combination of
the following operations: 1D temporal convolution, batch normalization, ReLu, and max pooling.
Next, we send the output of the encoder-TCN into the self-attention block to capture
long-range dependencies. After that, the decoder-TCN applies the 1D convolution and
up sampling to recover a feature map of the same dimension as visual encoding. Finally, the
output will be sent to a fully connected layer with softmax activation to get the prediction.
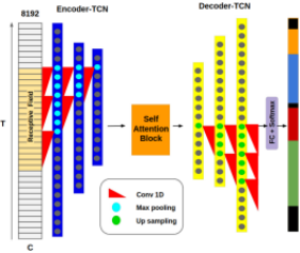
Fig 18 and 19 provide the structure of our model.
Figure
18. Overview. The model contains mainly three parts: (1) visual encoding, (2) encoder-decoder structure, (3) attention block
|
|
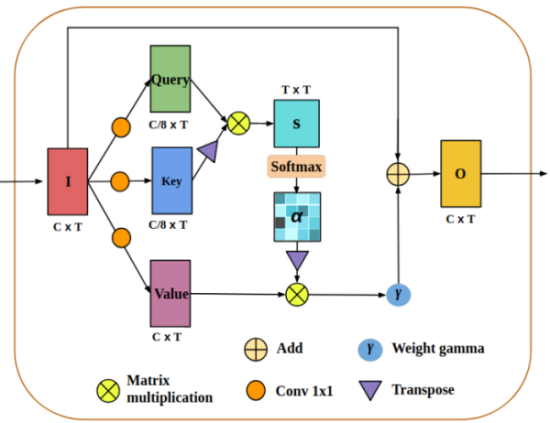
Figure
19. Attention block. This figure presents the structure of attention block
|
|
Result
We evaluated the proposed method on two daily-living activity datasets (DAHLIA, Breakfast) and achieved state-of-the-art performances. We compared with these following State-of the arts: DOHT, Negin et al., GRU , ED-TCN, TCFPN.
Table
2. Activity detection results on DAHLIA dataset with the average of view 1, 2 and 3. * marked methods have not been tested on DAHLIA in their original paper.
|
Model
|
FA1
|
F-score
|
IoU
|
mAP
|
| DOHT |
0.803 |
0.777 |
0.650 |
- |
| GRU |
0.759 |
0.484 |
0.428 |
0.654 |
| ED-TCN |
0.851 |
0.695 |
0.625 |
0.826 |
| Negin et al. |
0.847 |
0.797 |
0.723 |
- |
| TCFPN |
0.910 |
0.799
|
0.738 |
0.879
|
|
SA-TCN
|
0.921
|
0.788 |
0.740
|
0.862 |
Table
3. Activity detection results on Breakfast dataset.
|
Model
|
FA1
|
F-Score
|
IoU
|
mAP
|
| GRU |
0.368 |
0.295 |
0.198 |
0.380 |
| ED-TCN |
0.461 |
0.462 |
0.348 |
0.478 |
| TCFPN |
0.519
|
0.453 |
0.362 |
0.466 |
|
SA-TCN
|
0.497 |
0.494
|
0.385
|
0.480
|
Table
4. Average precision of ED-TCN on DAHLIA.
|
Activities
|
Background
|
House work
|
Working
|
Cooking
|
|
AP
|
0.36 |
0.65 |
0.95 |
0.96 |
|
Activities
|
Laying table
|
Eating
|
Clearing table
|
Wash dishes
|
|
AP
|
0.90 |
0.97 |
0.80 |
0.97 |
Table
5. Combination of attention block with other TCN-based model: TCFPN. (Evaluated on DAHLIA dataset)
|
Model
|
FA1
|
F-score
|
IoU
|
mAP
|
| TCFPN |
0.910 |
0.799
|
0.738 |
0.879 |
|
SA-TCFPN
|
0.917
|
0.799
|
0.748
|
0.894
|
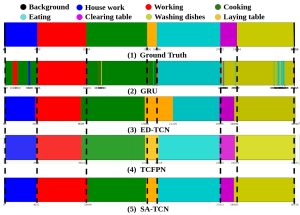
Figure
20. Detection visualization. The detection visualization of video 'S01A2K1' in DAHLIA: (1) ground truth, (2) GRU, (3) ED-TCN, (4) TCFPN and (5) SA-TCN.
|
|